Understanding the Internal Architecture of Java HashMap
HashMap is one of the most commonly used data structures in Java, providing an efficient way to store and retrieve key-value pairs. Its internal working is both fascinating and complex, ensuring optimal performance even in large-scale applications. Let’s delve into the internal mechanics of HashMap to understand how it works.
1. HashMap Structure
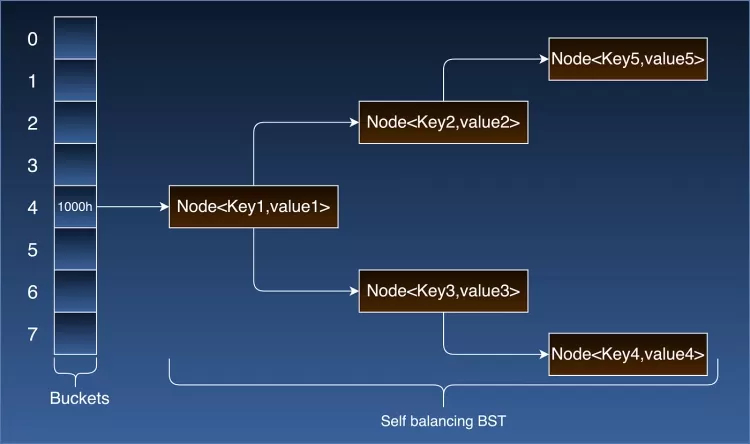
A HashMap is essentially an array of buckets. Each bucket is a container that holds key-value pairs. The array index for each key-value pair is determined by the key's hash code. This way, HashMap ensures that elements are evenly distributed across the array, minimizing collisions and optimizing retrieval time.
2. Hash Computation
The first step in storing a key-value pair in a HashMap is computing the hash code of the key. The hashCode() method of the key object is used to generate an integer hash code. To ensure that the hash codes are distributed uniformly and to minimize collisions, the hash code is further processed by a supplemental hash function. This ensures that the hash codes are more evenly distributed across the buckets.
3. Index Calculation
Once the hash code is computed, the next step is to determine the index in the array (bucket) where the key-value pair will be stored. This is done using the formula:
index = (n - 1) & hash
Here, "n" is the size of the bucket array, and "hash" is the computed hash value. The bitwise AND operation (&) ensures that the index is within the bounds of the array size.
4. Bucket Access and Collision Handling
When a key-value pair is added to the HashMap, the corresponding bucket at the calculated index is accessed. If the bucket is empty, a new node is created for the key-value pair and added to the bucket.
However, if the bucket already contains one or more nodes (due to hash collisions), Java 8 introduced a highly optimized collision handling mechanism. Initially, collisions are handled using a linked list. If the number of nodes in a bucket exceeds a threshold (default is 8), the linked list is transformed into a balanced binary tree (red-black tree). This transformation ensures that the time complexity for search operations in the worst-case scenario is reduced from O(n) to O(log n).
5. Rehashing and Load Factor
HashMap dynamically resizes itself when the number of elements exceeds a certain threshold, known as the load factor (default is 0.75). When the load factor threshold is breached, HashMap doubles the size of the bucket array and rehashes all existing keys. Rehashing involves recalculating the bucket index for each key based on the new array size.
6. Operations and Time Complexity
Put Operation:
-
Compute the hash code of the key.
-
Calculate the bucket index using the hash code.
-
Access the bucket and check if the key already exists.
-
If the key exists, update the value.
-
If the key doesn’t exist, add a new node to the bucket.
-
Get Operation:
-
Compute the hash code of the key.
-
Calculate the bucket index using the hash code.
-
Access the bucket and iterate through the nodes to find the key.
-
If the key is found, return the corresponding value.
-
If the key is not found, return null.
-
Remove Operation:
-
Compute the hash code of the key.
-
Calculate the bucket index using the hash code.
-
Access the bucket and iterate through the nodes to find the key.
-
If the key is found, remove the corresponding node and adjust the linked list or tree structure.
-
If the key is not found, do nothing.
-
The average time complexity for put, get, and remove operations in HashMap is O(1). However, in the worst-case scenario, where many collisions occur, the time complexity can degrade to O(log n) due to tree-based collision handling.
7. Key Takeaways
-
Uniform Distribution: The hash computation and index calculation ensure that elements are evenly distributed across the buckets.
-
Efficient Collision Handling: Java 8's linked list to tree transformation optimizes performance in collision-heavy scenarios.
-
Dynamic Resizing: HashMap dynamically resizes itself based on the load factor to maintain optimal performance.
-
Optimized Time Complexity: The average time complexity for basic operations is O(1), ensuring fast data retrieval and storage.
Understanding the internal workings of HashMap in Java reveals the sophistication behind this fundamental data structure. Its ability to efficiently store and retrieve key-value pairs, handle collisions, and dynamically resize makes it an invaluable tool for developers. By leveraging these internal mechanisms, HashMap ensures optimal performance and reliability in various applications.
What's Your Reaction?