Boosting Efficiency in Sequence Modeling: Introducing Mamba-Shedder for Structured State Space Models
In the ever-evolving landscape of machine learning, sequence modeling stands out as a cornerstone for a myriad of applications, from natural language processing (NLP) to time-series forecasting. Transformer architectures have long dominated this space, delivering impressive results across various domains. However, their success comes with significant computational and memory costs, especially as sequence lengths grow. Enter the world of Structured State Space Models (SSMs) and the latest innovation in model compression: Mamba-Shedder. In this blog post, we'll explore how Mamba-Shedder is revolutionizing the efficiency of SSM-based models, offering a promising alternative to the heavyweight Transformers.
The Dominance of Transformers and Their Limitations
Transformers, introduced by Vaswani et al. in 2017, have become the go-to architecture for sequence modeling tasks. Their ability to capture long-range dependencies through self-attention mechanisms has made them indispensable in NLP and beyond. Models like BERT, GPT, and their numerous derivatives have set new benchmarks in language understanding, generation, and more.
However, this prowess comes at a cost:
-
Quadratic Scaling: The computational and memory requirements of Transformers scale quadratically with the sequence length. This makes training and inference increasingly expensive as the input grows.
-
Large Memory Footprint: During generation, Transformers need to maintain extensive caches of previously seen tokens, leading to substantial memory usage.
These inefficiencies have spurred researchers to explore alternative architectures that can deliver similar performance with reduced computational overhead.
Enter Structured State Space Models (SSMs)
Structured State Space Models (SSMs) have emerged as a compelling alternative to Transformers for sequence modeling. Unlike Transformers, SSMs offer linear scaling with sequence length during training and maintain a constant state size during generation. This makes them inherently more efficient, especially for long sequences.
Notable SSMs: S4 and Mamba
-
S4 (Structured State Space Sequence Model): Introduced by Gu et al. in 2022, S4 leverages state space formulations to model sequences efficiently. Its structured approach allows for effective mapping from input to output signals with reduced computational complexity.
-
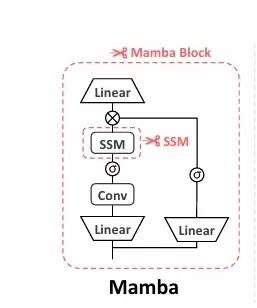
Mamba: Building on the foundation of S4, Mamba introduces selection mechanisms that make SSMs time-varying, enhancing their capability to handle complex sequence tasks that traditional SSMs struggle with. Additionally, Mamba incorporates hardware-aware algorithms to accelerate execution and minimize memory I/O.
-
Mamba-2: The latest iteration, Mamba-2, introduces state space duality (SSD) and grouped value attention (GVA) head structures, further optimizing parallelism and efficiency on hardware accelerators.
Hybrid Models: Combining the Best of Both Worlds
Hybrid models like Zamba and Hymba blend the strengths of Transformers and SSMs, aiming to harness the powerful in-context learning of Transformers with the efficiency of SSMs. These architectures employ innovative strategies such as shared attention mechanisms and parallel hybrid-head modules to achieve high throughput and reduced memory requirements.

The Quest for Efficiency: Model Pruning
While SSMs present a more efficient alternative to Transformers, there's still room for improvement. Model pruning, a well-established compression technique, offers a pathway to further enhance the efficiency of SSM-based models.
What is Model Pruning?
Model pruning involves systematically removing parts of a neural network to reduce its size and computational demands without significantly affecting performance. It operates at two levels:
-
Unstructured Pruning: Targets individual weights within the network, masking those deemed less important based on specific criteria.
-
Structured Pruning: Focuses on removing entire structural components, such as neurons or layers, leading to more substantial reductions in model size and computational overhead.
While pruning has been extensively explored for Transformer-based models, its application to SSMs has been less explored—until now.
Introducing Mamba-Shedder: Pruning for SSMs
Mamba-Shedder is a novel pruning solution tailored specifically for Selective Structured State Space Models (SSMs) like Mamba and its hybrid variants. Developed to tackle the inefficiencies inherent in large SSM-based models, Mamba-Shedder aims to reduce both model size and computational overhead while maintaining high accuracy.
How Does Mamba-Shedder Work?
-
Component Selection: Mamba-Shedder identifies specific structures within the SSM modules that contribute to redundancy. This targeted approach ensures that only the least critical components are pruned, preserving the model's core functionality.
-
Granularity Levels: Pruning is applied at various granular levels, allowing for a nuanced balance between efficiency gains and performance retention. This means that the pruning process can be fine-tuned to achieve optimal results based on the specific requirements of the deployment scenario.
-
Evaluation Metrics: The effectiveness of pruning is assessed based on the speedup achieved during inference and the impact on overall model accuracy. Mamba-Shedder is designed to maximize efficiency gains while ensuring that the model's performance remains largely unaffected.
Results That Speak Volumes
The implementation of Mamba-Shedder has yielded impressive results:
-
Speedup: Up to a 1.4x increase in inference speed, meaning that models can process sequences faster without requiring additional computational resources.
-
Minimal Accuracy Impact: Despite the reductions in size and computational overhead, the models retain their accuracy, demonstrating the effectiveness of the pruning strategy in eliminating redundancies without sacrificing performance.
The code for Mamba-Shedder is publicly available on GitHub: IntelLabs/HardwareAware-Automated-Machine-Learning, allowing researchers and practitioners to experiment with and build upon this promising approach.
Why Mamba-Shedder Matters
Bridging the Efficiency Gap
By effectively pruning SSM-based models, Mamba-Shedder addresses a critical bottleneck in sequence modeling: the trade-off between model complexity and operational efficiency. This advancement makes it feasible to deploy sophisticated sequence models in resource-constrained environments, such as mobile devices or edge computing platforms.
Enhancing Hybrid Architectures
For hybrid models that combine Transformers and SSMs, Mamba-Shedder provides valuable insights into how different architectural components interact. Understanding the tolerance of these models to pruning enables more informed decisions about where to streamline the architecture for maximum efficiency gains.
Paving the Way for Future Research
Mamba-Shedder opens new avenues for research in model compression tailored to alternative architectures. As the field continues to explore beyond Transformers, strategies like Mamba-Shedder will be essential in ensuring that these models remain practical and scalable.
Conclusion
The introduction of Mamba-Shedder marks a significant milestone in the quest for efficient sequence modeling. By targeting redundancies in Selective Structured State Space Models, this pruning solution not only enhances computational and memory efficiency but also maintains the high accuracy that makes these models so valuable. As the demand for more efficient and scalable machine learning models grows, innovations like Mamba-Shedder will play a pivotal role in shaping the future of AI.
Whether you're a researcher looking to optimize your models or a practitioner aiming to deploy efficient sequence models in real-world applications, Mamba-Shedder offers a promising tool in your arsenal. Dive into the code, experiment with pruning strategies, and contribute to the ongoing evolution of efficient sequence modeling!
Stay Updated: If you're passionate about machine learning advancements and model optimization techniques, stay tuned to our blog for more insights, tutorials, and the latest research breakthroughs.
Join the Conversation: Have questions or thoughts on Mamba-Shedder and model pruning? Leave a comment below or reach out to us on GitHub to share your experiences!
What's Your Reaction?