Introducing MAL-RAG: A Revolutionary Approach for Handling Multiple Abstraction Levels in Retrieval-Augmented Generation
In the evolving world of natural language processing (NLP), retrieval-augmented generation (RAG) has emerged as a promising solution to enhance the capabilities of large language models (LLMs). By integrating real-time data retrieval, RAG enables LLMs to generate more accurate, specialized, and contextually relevant answers without the need for extensive retraining. However, existing RAG methods primarily rely on retrieving fixed-size chunks of data, which struggle to handle complex queries that require information from multiple levels of abstraction. In this blog, we explore Multiple Abstraction Level Retrieval-Augmented Generation (MAL-RAG), a groundbreaking approach that mitigates these challenges and enhances the ability of LLMs to generate precise and comprehensive answers across diverse levels of abstraction.
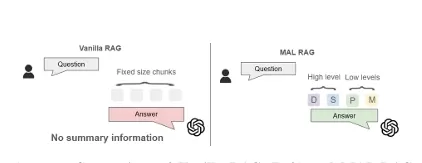
The Problem with Traditional RAG Models
Traditional RAG models operate by retrieving a fixed-sized chunk of information (such as a paragraph or a section) from external sources to assist in answering a query. This method works well for simpler, more straightforward questions but encounters limitations when the information needed spans multiple levels of complexity. For instance, a question requiring an answer that combines specific details from a paragraph, a section, and even a whole document would not be effectively handled by the current single-level RAG approach. Retrieving multiple chunks can lead to the infamous "lost in the middle" problem, where excessive information overwhelms the model, dilutes focus, and causes inefficiencies—especially when dealing with long documents.
In addition, when the retrieved information is not structured or abstracted at the right level, the model may struggle to provide a coherent response. This becomes a significant bottleneck in specialized fields like Glycoscience, where complex, domain-specific knowledge needs to be summarized across multiple levels—from sentences to sections to full documents.
Enter MAL-RAG: Handling Multiple Abstractions for Enhanced Answer Generation
MAL-RAG is a novel framework that takes the RAG concept to the next level by incorporating chunks at multiple levels of abstraction—multi-sentence-level, paragraph-level, section-level, and document-level. By leveraging these varying levels of information, MAL-RAG not only enhances the comprehension of scientific and technical content but also significantly improves the accuracy and relevance of generated responses.
How Does MAL-RAG Work?
-
Multiple Levels of Abstraction:
- Multi-sentence-level chunks (M) capture granular details from small pieces of text.
- Paragraph-level chunks (P) provide more context, summarizing key points from larger blocks of text.
- Section-level chunks (S) offer an even higher abstraction, summarizing entire sections or thematic groups of content.
- Document-level chunks (D) provide a broad overview, containing the main concepts of the entire document.
-
Chunk Generation Process: To ensure the information at each abstraction level is clear and manageable, the documents are split into the appropriate chunks:
- Map-Reduce Approach: Summaries are created at the paragraph level first, followed by the section level, and finally aggregated into the document-level summary. This approach helps avoid excessive chunk sizes while preserving key information at each level.
- Direct Retention for Lower Abstraction: For paragraph-level and multi-sentence-level chunks, the original content is retained, offering more detailed insights when needed.
-
Efficient Information Retrieval: MAL-RAG utilizes a retriever system that dynamically selects chunks based on the query’s requirements. By adjusting the number of chunks retrieved, the system ensures a balanced amount of information without overloading the model, thus improving retrieval efficiency and response relevance.
-
Answer Generation: Once the relevant chunks are retrieved, they are passed along with the input query to an Answer Generator, which uses a GPT-4 mini model to synthesize the final response.

Key Features and Benefits of MAL-RAG
-
Handling Complex Queries: The primary advantage of MAL-RAG is its ability to handle complex, multi-level queries that require detailed information from various layers of a document. Whether the query pertains to a specific sentence, a section, or an entire document, MAL-RAG ensures that the right level of information is retrieved and integrated into the answer.
-
Avoiding the "Lost in the Middle" Problem: By leveraging chunks from different abstraction levels, MAL-RAG mitigates the issue of excessive noise and irrelevant information that can arise from retrieving too many fixed-size chunks. This ensures the model maintains focus on the most relevant data and provides more accurate answers.
-
Optimized for Scientific Domains: MAL-RAG was specifically tested in the scientific domain of Glycoscience. By using a specialized dataset of Glyco-related papers, the framework demonstrated a 25.739% improvement in AI-evaluated answer correctness compared to traditional single-level RAG approaches. This proves its potential in domains requiring detailed, domain-specific knowledge.
-
Improved Efficiency: By utilizing varying levels of abstraction and dynamically adjusting chunk retrieval, MAL-RAG significantly reduces the computational cost and time required for data retrieval and processing. This efficiency is crucial for handling large-scale datasets, particularly in resource-constrained environments.
Comparison with Traditional RAG
Traditional RAG (Vanilla RAG) approaches typically operate by retrieving fixed-size chunks (usually paragraphs) from the reference documents. While these models are effective for basic question-answering, they often struggle with more complex queries requiring diverse levels of information. This results in incomplete or fragmented answers.
In contrast, MAL-RAG improves the process by dynamically selecting and integrating multiple levels of abstraction. As a result, it offers more accurate, coherent, and contextually rich answers, particularly in specialized domains like Glycoscience.
Conclusion: Shaping the Future of RAG with MAL-RAG
MAL-RAG represents a significant advancement in the field of retrieval-augmented generation, offering a more robust and flexible approach to generating specialized answers. By incorporating multi-level abstractions into the retrieval process, this framework solves the issues of data overload and imprecise responses, providing a more scalable solution for complex, real-world tasks.
The successful application of MAL-RAG to Glycoscience shows its immense potential for improving accuracy and efficiency in specialized domains. As we continue to push the boundaries of LLM performance, approaches like MAL-RAG will pave the way for more accurate, efficient, and adaptable AI systems that can provide meaningful insights across a wide range of disciplines.
How do you think MAL-RAG could impact other scientific domains, such as medicine or law? Share your thoughts in the comments below!
What's Your Reaction?