Enhancing Retrieval-Augmented Generation with Multiple Abstraction Levels for Specialized Knowledge Retrieval
In the fast-paced world of artificial intelligence (AI), large language models (LLMs) have become indispensable, powering everything from translation services to chatbots. While LLMs have excelled in general language tasks, they often fall short when faced with specialized, technical questions that require domain-specific expertise. Whether it's answering intricate queries about scientific research or delving into complex legal issues, LLMs can struggle to provide accurate, up-to-date responses.
This challenge is particularly apparent in scientific research, where knowledge is dense, structured, and constantly evolving. To address this, a new approach called Retrieval-Augmented Generation (RAG) has emerged, combining the generative power of LLMs with the precision of information retrieval. But even RAG has limitations, especially when handling questions that require multi-layered, detailed insights from scientific papers.
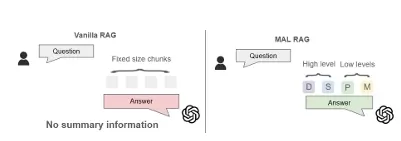
In response to this gap, researchers have introduced a novel solution: Multiple Abstraction Level Retrieval-Augmented Generation (MAL-RAG). This approach enhances the traditional RAG framework by incorporating chunks of text at varying levels of abstraction, from sentences and paragraphs to entire sections and documents. By doing so, MAL-RAG can produce more accurate and contextually relevant answers, even for highly specialized questions.
Understanding the Core Concepts:
Before diving into the innovations of MAL-RAG, it's essential to understand the core concepts of Retrieval-Augmented Generation (RAG) and the challenges it faces in specialized domains like science.
-
Retrieval-Augmented Generation (RAG): At its core, RAG combines two powerful mechanisms. First, it retrieves relevant chunks of information from external sources, such as databases or documents. Then, it uses this information to generate a response that is informed by the retrieved context. In scientific domains, this means combining the power of an LLM with a vast library of research papers, articles, and journals.
-
Abstraction Levels: The concept of abstraction refers to the degree of detail in the information retrieved. For instance, a document-level chunk provides a broad overview of a topic, while a paragraph-level chunk offers more specific details. The challenge lies in determining which level of abstraction is most suitable for a given query and retrieving information from multiple levels as needed.
The Challenge Addressed by the Research:
Traditional RAG models have made significant strides in improving AI-generated answers. However, these systems typically retrieve information at a single level of abstraction, such as entire paragraphs or sections. This one-size-fits-all approach works for some queries, but it falters when a question requires a combination of both general knowledge (document-level) and specific insights (section- or paragraph-level).
For example, imagine a complex question in Glycoscience, a field studying carbohydrates and their biological roles. An accurate response might require information about the overall molecular structure (document-level), but also the specific interactions between molecules in a particular experiment (paragraph-level). Traditional RAG models struggle to retrieve the right mix of broad and specific details, often leading to incoherent or incomplete answers.
The issue of "lost in the middle" occurs when the model is overloaded with excessive context but fails to extract the most relevant information, compromising the accuracy of the response.
A New Approach: The Authors’ Contribution:
To address this issue, the researchers behind MAL-RAG propose a multi-layered approach to information retrieval. Instead of relying on a single chunk size, MAL-RAG retrieves data from multiple abstraction levels:
-
Multi-Sentence-Level Chunks (M): These smaller, more focused chunks allow the model to zero in on very specific details, such as an individual experiment's findings or a concise summary of a molecular interaction.
-
Paragraph-Level Chunks (P): These offer a balanced level of detail, providing both context and specific information relevant to the question at hand.
-
Section-Level Chunks (S): For deeper exploration, these chunks cover more substantial parts of a paper, allowing the model to draw on more comprehensive information.
-
Document-Level Chunks (D): These chunks provide the broadest context, ideal for questions that require a general overview or big-picture understanding of a topic.
By combining chunks from these varying levels, MAL-RAG ensures that the model receives just the right amount of context, preventing information overload while maintaining the accuracy of the generated answer.
Experimental Setup: Demonstrating Effectiveness in Glycoscience
To demonstrate the power of MAL-RAG, the researchers applied their framework to a specific domain: Glycoscience, which focuses on the structure and function of carbohydrates. They curated a dataset of over 7,600 academic articles on the subject, and segmented them into document, section, paragraph, and multi-sentence chunks.
Using a set of 1,118 Q/A pairs based on Glycoscience topics, they tested how well MAL-RAG could generate accurate, detailed answers. These questions spanned everything from detailed molecular structures to broader biological processes, providing a robust test of the model's capabilities.
Key Contributions and Findings:
-
Improved Answer Accuracy: MAL-RAG significantly outperformed traditional RAG models, with a 25.739% improvement in answer correctness on Glycoscience questions. By leveraging multi-level abstraction, it could generate more precise, specialized answers.
-
Efficient Use of Information: The ability to pull information from multiple levels allowed MAL-RAG to avoid the pitfalls of traditional RAG systems, where excessive or irrelevant information could overwhelm the model.
-
Flexibility in Handling Complex Queries: MAL-RAG demonstrated adaptability in handling questions that required different levels of detail, making it effective for a wide range of scientific queries.
-
Scalability: The model also scaled well with large datasets, making it suitable for real-world applications in rapidly growing fields like scientific research.
Performance Comparison:
In a performance comparison with other RAG methods, MAL-RAG significantly outperformed its counterparts in several key metrics, including answer correctness, context precision, and context utilization:
| RAG Approach | Answer Correctness | Context Precision | Context Utilization | F1 Score |
|---|---|---|---|---|
| Vanilla RAG | 43.05% | 59.24% | 80.25% | 50.94% |
| Single-Abstraction RAG | 57.25% | 71.51% | 80.36% | 59.49% |
| MAL-RAG | 68.79% | 80.55% | 87.55% | 75.48% |
These results highlight the superior performance of MAL-RAG, particularly in its ability to make effective use of context and generate accurate, relevant answers.
Conclusion: Advancing Scientific Question Answering
The introduction of MAL-RAG represents a significant step forward in the evolution of Retrieval-Augmented Generation, particularly for complex scientific domains. By incorporating multi-level abstraction in its retrieval process, MAL-RAG allows AI systems to generate more accurate and contextually relevant answers, even for highly specialized questions. The impressive results in Glycoscience show the potential of this approach for other fields, such as medicine, biology, and beyond.
As AI continues to advance, the ability to retrieve and process information from multiple levels of abstraction will become increasingly crucial, enabling more robust, adaptable, and efficient AI systems.
What do you think about the potential of multi-level abstraction in improving AI models across other industries? Could this approach be the key to answering complex domain-specific questions in fields like law or finance?
What's Your Reaction?

















