Enhancing Cloud Infrastructure Monitoring with AI-Driven Anomaly Detection
Cloud services are pivotal to modern enterprises, supporting everything from everyday applications to critical infrastructure. However, ensuring their stability and reliability can be complex. As cloud systems grow, anomalies—unusual deviations from expected behavior—often arise, impacting the performance, security, and user experience. Identifying and addressing these anomalies is crucial, and with the help of advanced machine learning techniques, we can significantly improve the way we monitor and manage cloud infrastructure.
In this post, we explore a powerful Anomaly Detection System that leverages cutting-edge Large Language Models (LLMs) and Deep Learning (DL) techniques, implemented as a cloud-based service. The system is designed to improve the reliability of cloud infrastructure through real-time anomaly detection, predictive analytics, and data-driven decision-making.
The Importance of Anomaly Detection in Cloud Infrastructure
Cloud infrastructures are composed of multiple components like servers, networking equipment, and power systems, all of which need to be carefully monitored to ensure smooth operations. Small anomalies in any of these areas can snowball into significant failures, leading to system downtimes or data breaches. For this reason, having a robust anomaly detection framework is crucial for cloud service providers.
Traditional anomaly detection methods often struggle with high-dimensional data and the combinatorial nature of possible anomalies. They also fail to predict anomalies outside the validation set, limiting their usefulness in the long run. Our system addresses these challenges with an efficient, automated framework for detecting error slices—groups of failure cases sharing similar characteristics. This allows for immediate detection and resolution of cloud infrastructure issues.

LLM-Assisted Anomaly Modeling
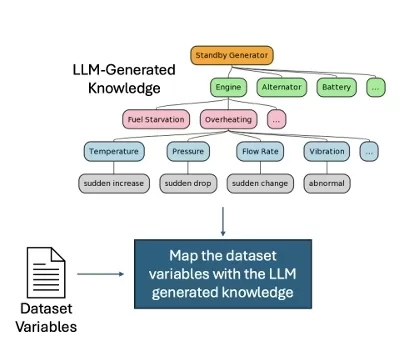
The core innovation behind this anomaly detection system lies in the use of Large Language Models (LLMs) for anomaly modeling. By utilizing pre-trained LLMs like Llama or Mistral, we generate diverse failure modes, identify the corresponding metrics for monitoring, and map them to relevant cloud infrastructure variables. This step ensures that anomaly models are tailored to specific components of the cloud infrastructure, such as:
- Servers (CPU, memory, storage)
- Network components (routers, switches, load balancers)
- Security components (firewalls, intrusion detection systems)
- Power systems (UPS, transformers)
For example, using LLMs, we can generate failure modes for components like standby generators used in hospitals or data centers, then match these failures with the right metrics to monitor.
Data Capture and Storage
The first stage in the Anomaly Detection System involves capturing large volumes of data from the cloud infrastructure. This data includes important metrics like:
- Network traffic
- CPU utilization
- Disk I/O
- Memory usage
The collected data is then stored in a Cloud Object Storage for future analysis, with pipelines feeding the data into pre-processing stages. This ensures that the data is ready for processing by the Anomaly Detection API.
The Role of Deep Learning in Anomaly Detection
At the heart of our system is a deep neural network (DNN) AutoEncoder called ReconstructAD. This autoencoder-based model is designed to learn the normal patterns of cloud infrastructure metrics and identify unusual behaviors that indicate potential issues. The model works by reconstructing input data (e.g., CPU usage, network traffic) and comparing the reconstruction error to determine if the behavior is anomalous.
Key Features:
-
Chi-Square Distribution: We use this statistical method to compute p-values as anomaly scores. This allows us to determine whether an anomaly is significant enough to warrant further investigation.
-
Principal Component Analysis (PCA): This technique helps identify the most influential metrics contributing to anomalies in multivariate data scenarios, ensuring that we focus on the most critical aspects of system behavior.
-
Threshold Setting: The threshold for detecting anomalies is adjustable, allowing users to balance between false positives and false negatives, depending on the sensitivity needed.
Visualization for Monitoring and Action
Once anomalies are detected, it's essential for engineers to visualize and act on them in real-time. To achieve this, we've integrated a Grafana-based dashboard, allowing Site Reliability Engineers (SREs) and other personas to monitor anomalies effectively. The dashboard provides a clear visualization of detected spikes and anomalies in various cloud resources, such as Virtual Server Instances (VSIs) and CPU usage.
Example Dashboards:
- CPU Usage Percent Spikes: Visualized anomalies for sudden increases in CPU utilization.
- Network Traffic Fluctuations: Detection of unusual network activity, which could indicate security issues or system overload.
By providing these insights, the system enables quicker identification of underlying issues, which helps reduce downtime and prevent major failures.
Personas Benefiting from the Anomaly Detection System
Our anomaly detection system is designed with different personas in mind, each with unique needs and requirements:
1. Site Reliability Engineers (SREs)
- Challenges: SREs spend a considerable amount of time manually sifting through dashboards and monitoring data to identify issues.
- Solution: The automated anomaly detection system reduces the manual effort by automatically flagging issues and providing real-time visualizations, allowing SREs to focus on resolving critical problems.
2. Cloud Services Developers
- Challenges: Developers need to ensure that cloud applications are running smoothly and efficiently, with minimal downtime.
- Solution: By integrating anomaly detection into the development pipeline, developers can proactively identify potential issues and optimize application performance.
The Future of Cloud Monitoring with AI
The introduction of AI-powered anomaly detection is transforming the way cloud infrastructure is monitored and managed. By utilizing LLMs, deep learning, and advanced statistical methods, this system not only improves reliability and efficiency but also provides deep insights into cloud behavior. As cloud infrastructure continues to scale, this framework will play a crucial role in ensuring the smooth operation of critical services and applications.
In summary, by automating the anomaly detection process and providing real-time insights into system behavior, we are paving the way for more robust, scalable, and efficient cloud infrastructure management.
Discussion Question: How do you think integrating AI into cloud monitoring will impact long-term scalability and reliability in enterprise applications?
What's Your Reaction?

















