Distilling Large Language Models for Network Active Queue Management
In recent years, network traffic management has become a critical challenge, especially as demands for ultra-low latency communication increase. Traditional methods for managing packet traffic, such as Active Queue Management (AQM), often struggle in dynamic environments and require a high level of manual effort for fine-tuning. A promising solution lies in the use of Large Language Models (LLMs), which excel at pattern recognition, contextual understanding, and few-shot learning. In this post, we explore the novel AQM-LLM framework, which distills LLMs for improved congestion control and queue management in Low Latency, Low Loss, and Scalable Throughput (L4S) networks.
Introduction: A Shift in Network Traffic Management
Network management has traditionally relied on rule-based AQMs, which use mathematical models to optimize packet traffic based on predefined rules. Algorithms like Random Early Detection (RED) and Controlled Delay (CoDel) use queue length and delay as primary metrics to manage network buffers. While these approaches work well in many scenarios, they struggle with the complexities of modern networks, especially in dynamic environments like 5G, Wi-Fi, and satellite networks. These environments experience fluctuating network conditions such as link quality variations, traffic patterns, and interference, making rule-based methods cumbersome and inefficient.
This is where machine learning (ML) methods, particularly Deep Learning and Reinforcement Learning (RL), come into play. These methods enable network systems to learn from data and dynamically adjust to changing conditions. However, they come with challenges such as scalability, robustness, and computational efficiency, particularly when applied to AQM systems.

Enter LLMs for AQM Optimization
LLMs like GPT, Llama, and OPT have shown impressive capabilities in language understanding, reasoning, and generalization across various tasks. These models, with their self-attention mechanism, are well-suited for analyzing network traffic data, understanding dependencies, and making proactive congestion management decisions. However, adapting these models for AQM requires addressing some key challenges:
- Diverse Inputs: Network data is complex and includes time-series data (e.g., queue delay) and scalar values (e.g., burst allowance).
- Inference Latency: LLMs traditionally output results token by token, which can be too slow for real-time AQM updates.
- Distillation Costs: Fine-tuning LLMs for network management is resource-intensive, especially for decision-making tasks.
To address these challenges, we propose AQM-LLM, a system that distills LLMs for AQM with minimal manual effort and optimized performance for Low Latency, Low Loss, and Scalable Throughput (L4S) networks.
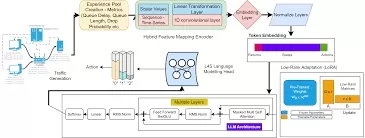
The AQM-LLM Architecture
The AQM-LLM framework is designed to optimize AQM tasks such as packet enqueueing, packet dropping, and ECN marking. Our system is built around three core modules:
- State Encoder: This module processes various network metrics (e.g., queue size, delay) and converts them into token-like embeddings that LLMs can understand and utilize effectively.
- L4S-LM Head: A specialized head that integrates with the LLM, directly mapping outputs to congestion prevention actions. This design reduces inference latency and prevents hallucinated outputs.
- Data-Driven Low-Rank L4S Adaptation (LoRA): LoRA finetunes the LLM for AQM tasks using reinforcement learning (RL) and distillation, drastically reducing training costs and memory usage.
1. State Encoder: Processing Network Data
The State Encoder is responsible for handling diverse network data inputs, such as time-series queue delay or scalar metrics like burst allowance. It uses feature encoders that specialize in handling different data types. For example:
- Scalar Data: Fully connected layers process scalar inputs, like queue size.
- Time-Series Data: 1D convolutional layers capture temporal patterns in sequential data, such as queue delay trends.
After encoding, the features are projected into a token-like space compatible with the LLM, ensuring seamless integration.
2. L4S-LM Head: Efficient Decision Making
Traditional LLMs generate responses iteratively, causing significant latency. Our L4S-LM Head overcomes this limitation by generating a valid output in a single round of inference. It predicts a probability distribution over possible congestion management actions (enqueue, drop, or mark) without the need for token-by-token generation. This leads to faster response times and better scalability for real-time AQM systems.
3. LoRA: Efficient Distillation
The Data-Driven Low-Rank L4S Adaptation (LoRA) technique significantly reduces the computational cost of distilling LLMs. LoRA finetunes the model using RL with pre-collected data, reducing GPU memory usage by 64% and training time by 15.1%. This adaptation makes it feasible to deploy LLMs for real-time AQM tasks, addressing the challenge of resource-intensive training.
Implementation and Evaluation
We implemented the L4S-LLM framework on FreeBSD-14, an open-source platform that allows integration with LLMs for AQM. Our implementation includes modules for both user and kernel space, providing the necessary infrastructure for testing and experimentation.
In our extensive evaluations, we tested L4S-LLM on various network scenarios and found that it effectively:
- Enhanced queue management by proactively identifying congestion and reducing latency.
- Reduced packet loss and prevented congestion using ECN marking and packet dropping strategies.
- Improved network performance, especially in unseen or dynamic network conditions.
These results demonstrate that AQM-LLM not only outperforms traditional AQM systems but also reduces the manual effort and complexity typically required in network management tasks.
Conclusion
The AQM-LLM framework represents a significant advancement in network traffic management, leveraging the power of Large Language Models to improve Active Queue Management systems. By combining a state encoder, an efficient L4S-LM head, and the LoRA finetuning technique, we show that LLMs can effectively address the challenges of congestion management, latency reduction, and scalability in modern networks.
Our approach also offers a flexible and efficient solution for integrating LLMs into network management systems with minimal manual intervention. The open-source platform on FreeBSD-14 facilitates broader experimentation and recognition by the Internet Engineering Task Force (IETF), paving the way for wider adoption of LLM-based AQM systems in the future.
Discussion Prompt: How do you think the integration of Large Language Models in network management will impact the future of 5G/6G or satellite networks with increasingly complex and dynamic traffic patterns?
What's Your Reaction?

















