Block-LoRA: A Low-Rank Adaptation Framework for Efficient Few-Shot Classification with CLIP
In recent days, Vision-Language Models (VLMs) like CLIP (Contrastive Language-Image Pretraining) have demonstrated significant performance in a wide range of tasks. These models, which jointly train an image and text encoder using a contrastive learning approach, can generalize well to new tasks, particularly few-shot learning. However, the large number of parameters in these models makes them challenging to fine-tune for new tasks, especially when computational resources are limited.
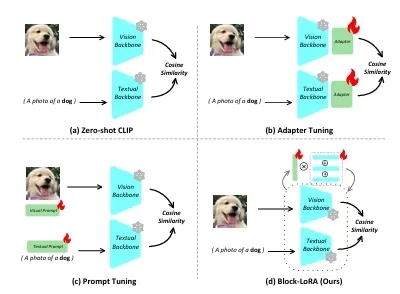
The challenge of efficiently adapting VLMs to few-shot learning tasks while minimizing training costs has led to the development of various techniques, such as Prompt-based Fine-Tuning and Adapter-based Fine-Tuning. While these methods have been effective, they introduce additional computational overhead due to the extra modules they incorporate into the CLIP model. More recently, LoRA (Low-Rank Adaptation) has been proposed to reduce this overhead by introducing low-rank matrices into the model for efficient fine-tuning. However, even LoRA suffers from redundancy, which can reduce its effectiveness in certain tasks.
In this paper, we propose a novel Block Matrix-based Low-Rank Adaptation framework called Block-LoRA. This method addresses the redundancy problem of vanilla LoRA by partitioning the low-rank decomposition matrix into smaller sub-matrices, which are shared across tasks. This approach not only reduces the number of parameters that need to be trained but also reduces the computational cost during fine-tuning by simplifying matrix multiplication operations into additions.
Key Contributions:
- Block-LoRA reduces redundancy in LoRA's structure by partitioning the low-rank matrices into smaller blocks, which are shared across tasks. This improves efficiency and reduces the computational overhead during fine-tuning.
- Reduction in Parameters and Computational Cost: The Block-LoRA framework significantly reduces the number of parameters compared to previous methods while maintaining competitive performance on few-shot classification tasks.
- Efficiency in Few-Shot Learning: Block-LoRA allows CLIP to be fine-tuned efficiently, even with limited computational resources (tested on a single 24GB GPU).
- No Added Inference Latency: Unlike many other fine-tuning methods, the Block-LoRA approach does not introduce additional inference latency, making it suitable for real-time applications.
Problem Context
Few-shot learning is a critical aspect of modern machine learning, particularly in settings where labeled data is scarce. In traditional machine learning approaches, models require a substantial amount of labeled data to perform well. Few-shot learning, however, aims to enable models to adapt to new tasks with only a few labeled samples. VLMs like CLIP have shown promising results in few-shot learning by leveraging their pre-trained knowledge from large-scale multimodal datasets.
However, adapting these large models to specific tasks often requires fine-tuning, which can be computationally expensive and resource-intensive. This is particularly problematic when trying to fine-tune large VLMs like CLIP, which have millions of parameters. Techniques like LoRA and adapter-based fine-tuning aim to address these challenges by reducing the number of trainable parameters, but they still introduce some computational overhead.
Approach: Block-LoRA
Our proposed approach, Block-LoRA, takes inspiration from the LoRA method but improves upon it by partitioning the low-rank decomposition matrix into smaller blocks. These smaller blocks are shared across different tasks, reducing redundancy and lowering the number of parameters to be trained. This partitioning allows us to achieve the following:
-
Parameter Efficiency: By sharing sub-matrices across tasks, we reduce the number of parameters that need to be trained, making the fine-tuning process more efficient.
-
Reduced Computational Cost: During the forward propagation, the use of shared sub-matrices simplifies complex matrix multiplications into simpler additions, leading to faster computation.
-
Task Flexibility: Unlike other methods that require modifying the original model for each new task, Block-LoRA allows us to replace only the low-rank sub-matrices when switching between tasks, making it easier to adapt to new tasks without modifying the original pre-trained model.
-
No Inference Latency: Since the low-rank matrices are merged into the original model weights during inference, Block-LoRA does not introduce additional latency during real-time use, making it ideal for practical applications.
Experimental Results
We conducted extensive experiments on 11 benchmark datasets to evaluate the performance of Block-LoRA in few-shot classification tasks. Our results demonstrate that Block-LoRA outperforms existing state-of-the-art (SOTA) methods in terms of both classification performance and computational efficiency.
-
Few-Shot Learning: Block-LoRA achieves competitive classification accuracy, comparable to other advanced few-shot learning techniques, while significantly reducing the number of parameters to be trained.
-
Cross-Dataset Evaluation: We tested Block-LoRA across multiple datasets and observed consistent performance improvements, validating its effectiveness across diverse tasks.
-
Domain Generalization: Block-LoRA also demonstrates robust performance in domain generalization tasks, where the model is required to generalize to new, unseen domains with minimal labeled data.
Conclusion
In summary, Block-LoRA provides an efficient and scalable solution for fine-tuning CLIP on few-shot classification tasks. By partitioning the low-rank adaptation matrices and sharing them across tasks, Block-LoRA reduces computational overhead and the number of parameters to be trained, making it a promising technique for adapting large pre-trained models like CLIP to new tasks efficiently.
Our approach also maintains the benefits of LoRA, including task flexibility and no added inference latency, while offering significant improvements in efficiency. The extensive experimental results validate that Block-LoRA is a powerful tool for efficient fine-tuning in few-shot learning, providing a foundation for further research and real-world applications in resource-constrained environments.
What's Your Reaction?